尚硅谷大数据6.0
技术课程和项目课程区别
框架和系统的区别
- 课程知识点
技术课程知识点非常的多, 非常的散
项目课程知识点非常的集中 - 知识点深度和广度
知识点深度和广度的问题
技术课程的知识点很多, 不会很深
项目课程: 采集项目 & 数据仓库项目
数据管理平台中的核心管理模块, 可以分开来开发 (独立)
- 从功能角度
采集项目: 以数据的采集,传输为主
数据仓库: 以数据的存储和计算为主 - 从技术的角度
采集项目: flume, kafka, datax, maxwell
数据仓库项目: Mysql, HDFS, Spark(计算),flink(实时), MR, Hive
为什么学 Spark?
数据库 & 数据仓库
- 从名称上区别
数据库: database
数据仓库: data warehouse
warehouse 有物流中心的仓库的意思, 更多的是为了运输.
这就是数据库和数据仓库的区别 - 从数据的来源进行区分
database: 企业中基础核心的业务数据
data warehouse: 数据库中的数据 - 从数据的存储进行区分
database: 核心作用是查找业务数据
(行式存储,定位需要用到索引快速定位到某一行) 不能存储海量数据
data warehouse: 核心作用就是统计分析数据
(列式存储,所以不需要索引)
行为数据, 业务数据
什么是行为数据? 什么是业务数据?
业务服务器会产生行为数据用业务日志记录
数据仓库架构
数据仓库的核心功能: 统计分 Spark, MR, Flink
Spark 中使用 RTD(ReceivingTrackerData) 需要用到 Scala
Spark On Hive: Spark 解析 sql
Hive On Spark: Hive 解析 sql(因为有 hadoop)
统计分析的基本步骤
(wordCount) 为例
Sql 实现 WordCount 专题
如果将数据库 (MySQL) 直接作为数据仓库 (Hive) 的数据源会怎么样?
- 业务数据的数据存储行为为行式存储, 而数据仓库的数据要求是列式数据
- 业务数据库中存储的数据不是海量数据, 但是数据仓库要求的是海量数据
- 数据库不是为了数据仓库服务的, 直接调用数据库作为数据仓库的数据源会对数据库的服务产生影响.
数据仓库应该设计一个自己的数据源, 为了代替数据和补充.
数据仓库的开发使用 SQL 语言进行处理, 那么数据的处理步骤中应该采用什么方法
需要将数据转换为结构化数据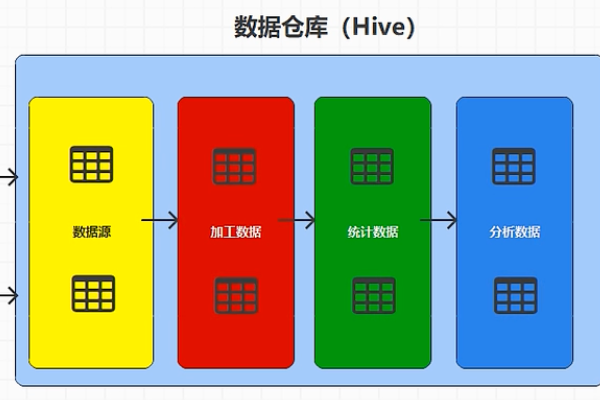
rdd.cache(缓存) spark 中
数据采集
HDFS 的引出
怎么把数据库的资源同步到数据仓库的数据源中? 首先必须知道采集项目和数据仓库项目具有耦合性 (必须要先知道数据库的表结构)
如何同步开发?
需要解耦合
即同步数据库和数据仓库数据源的中件键, 技术上怎么实现?
hive(table)=> HDFS(file) hive 的底层是 HDFS
所以使用 HDFS 来做中间件.
但如果数仓用的不是 Hive, 就不太建议用 HDFS 了.
架构: 把数据库中的数据通过数据采集进入 HDFS 的架构
日志文件通过使用 Flume , 业务数据通过 DataX,Maxwell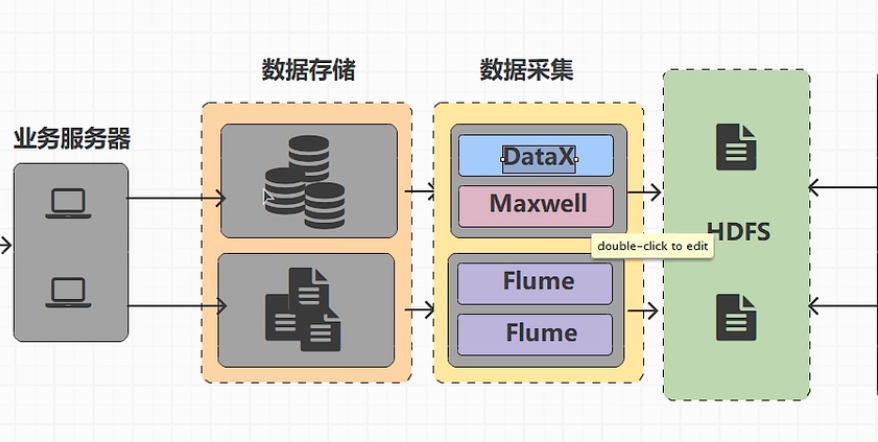
数据采集问题 1
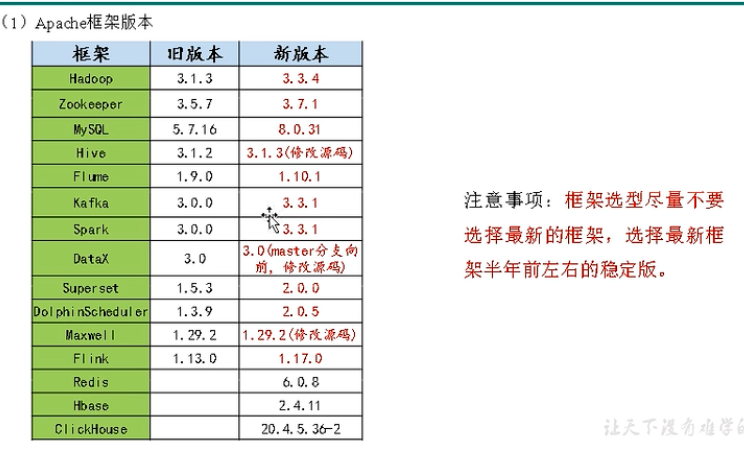
项目技术如何选型?
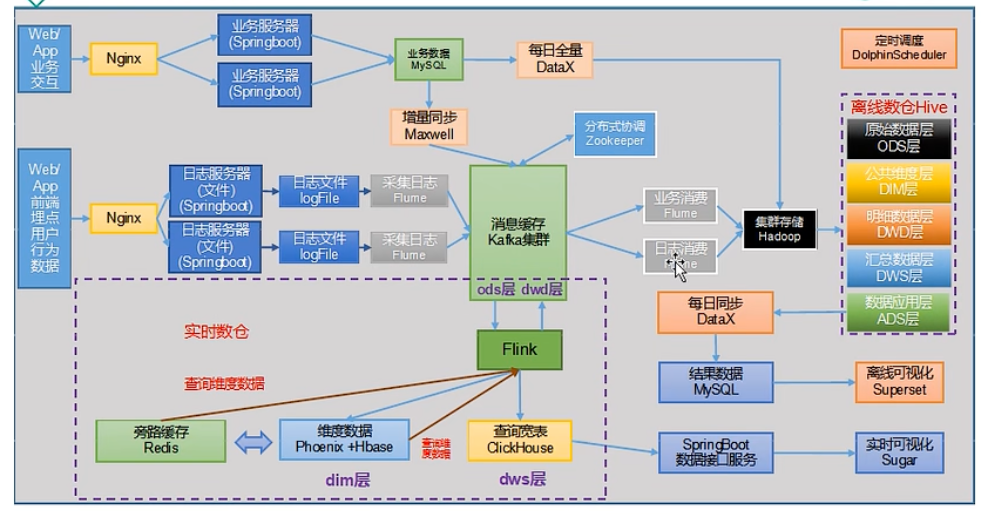
框架发行版本如何选型 (Apache,CDP)?
如何确定集群规模?
用户行为日志采集
埋点: "tracking point"
页面浏览记录, 动作记录, 曝光记录, 启动记录, 错误记录.
数据同步的格式:
- 用户行为日志数据
格式: JSON