MySql子目录
About 3 min
Sql 日志
redo log 和 bin log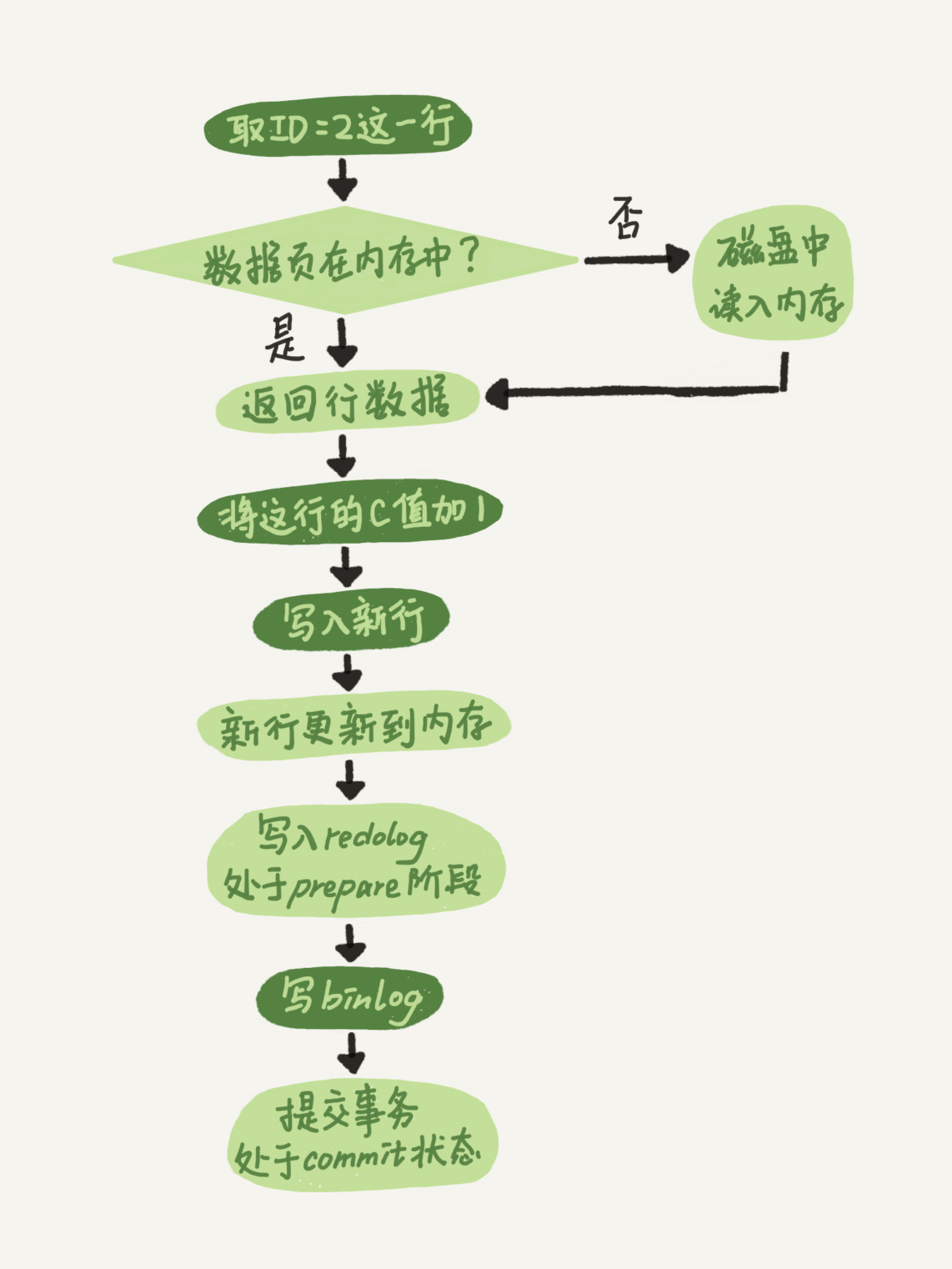
binlog 会记录所有的逻辑操作,并且是采用“追加写”的形式。
事务隔离
ACID(atom/consis/isol/dura)
sql 标准的事务隔离级别:
读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )
- 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
索引
索引的出现其实就是为了提高数据查询的效率,就像书的目录一样
哈希索引
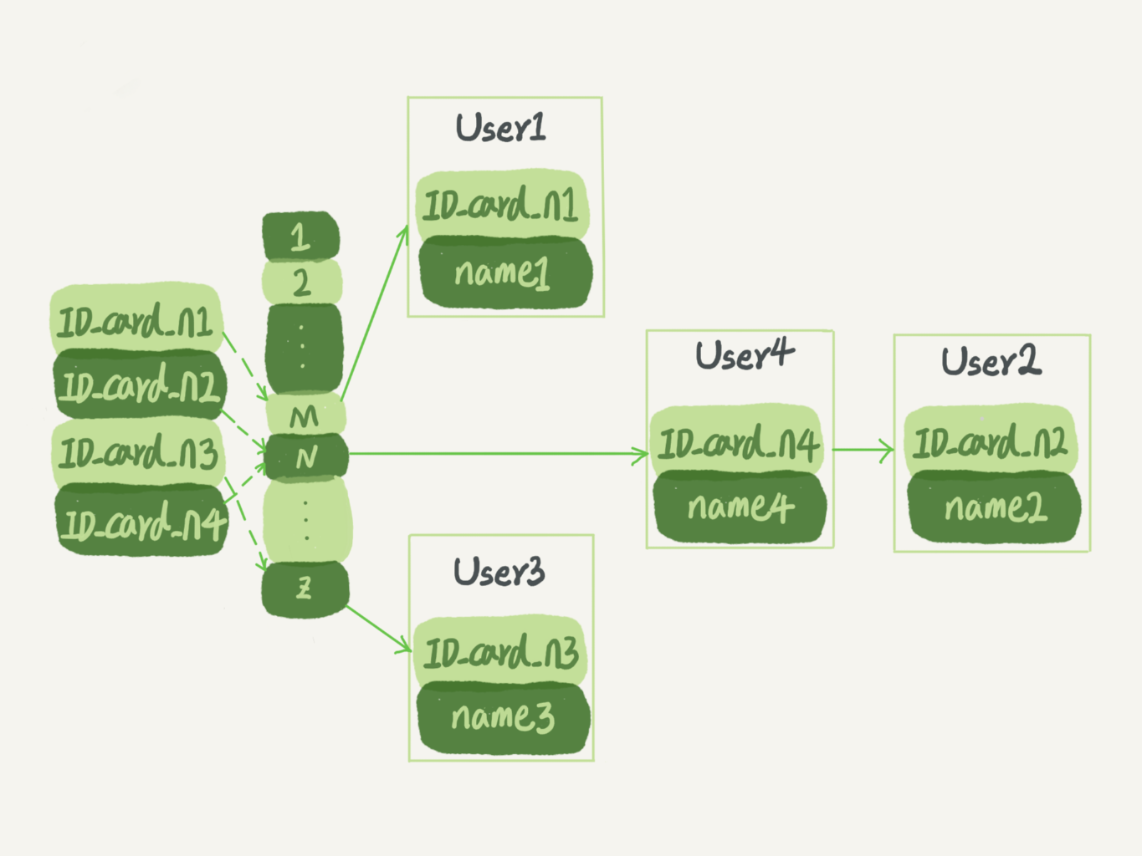
哈系索引做区间查询是很慢的
有序数组索引
有序数组索引只适用于静态存储引擎
因为更新麻烦
N 叉搜索树 (B 树) 索引
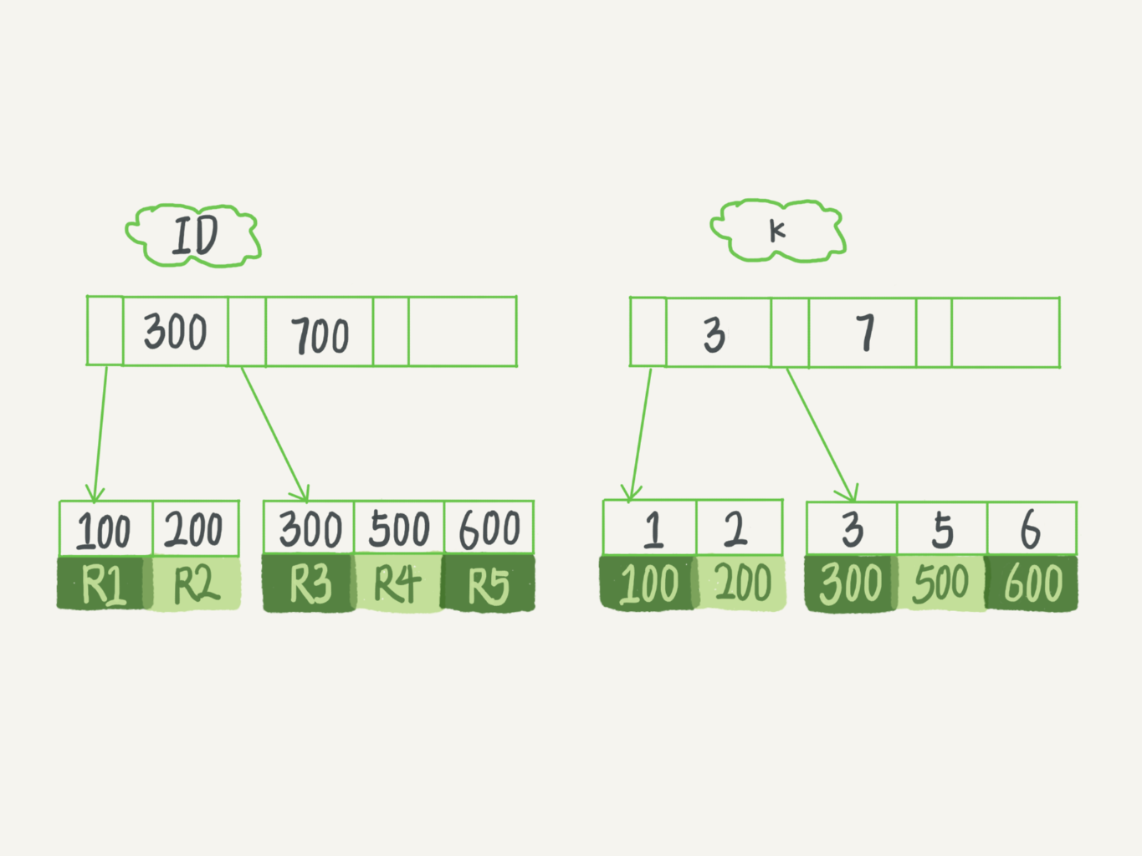
主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index
这样的话使用非主键索引获得了 ID 后, 会拿主键在主键索引树上再搜索一遍.
索引 +
执行 select * from T where k between 3 and 5,需要执行几次树的搜索操作,会扫描多少行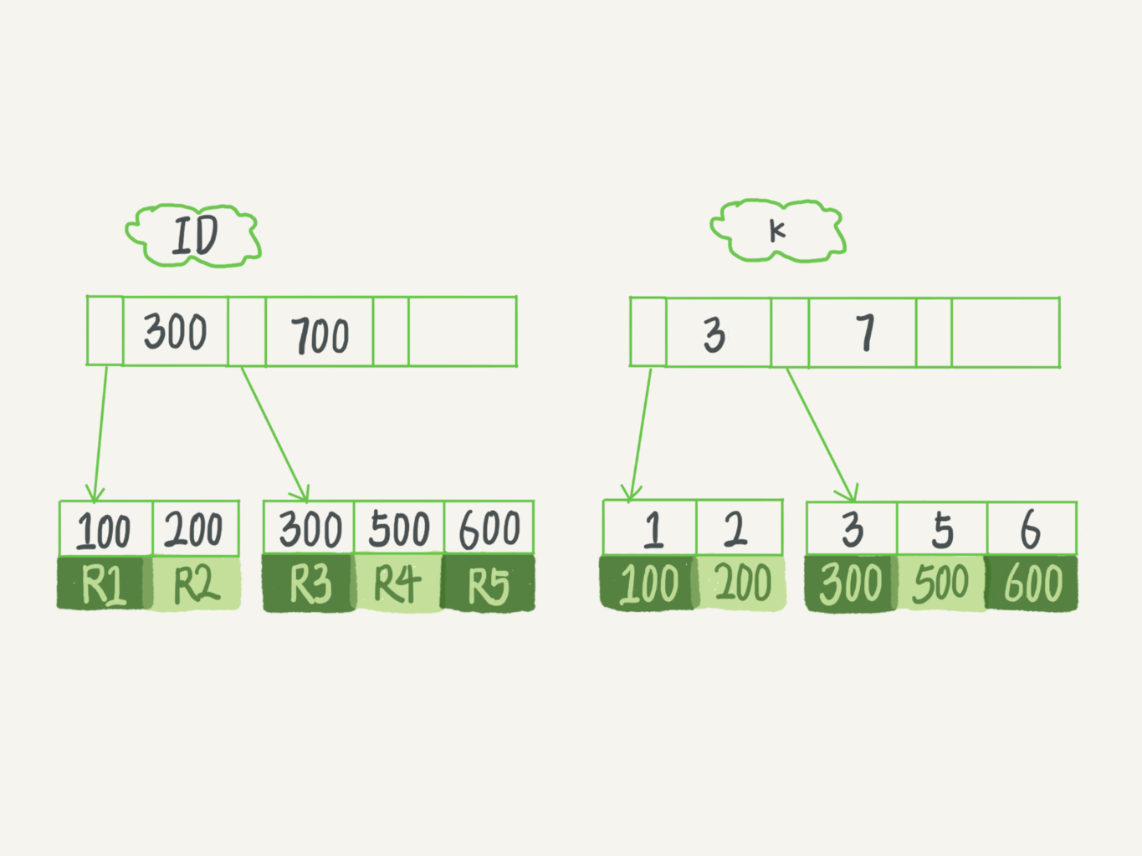
现在,我们一起来看看这条 SQL 查询语句的执行流程:
- 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500;
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值 k=6,不满足条件,循环结束。
在这个过程中,回到主键索引树搜索的过程,我们称为回表。可以看到,这个查询过程读了 k 索引树的 3 条记录(步骤 1、3 和 5),回表了两次(步骤 2 和 4)。
覆盖索引
不需要回表的索引, 即在构建索引的时候建立联合索引, 联合索引覆盖了需要查找的内容
最左前缀原则
建立索引的时候, 安排索引内的字段顺序能加大查找速度
- 如果既有基于
a的查询,也有基于a和b的联合查询,那么(a, b)的索引顺序可以同时支持这两种查询。 - 如果你还需要频繁地单独查询
b字段,那么除了(a, b)联合索引外,可能还需要一个单独的b索引。